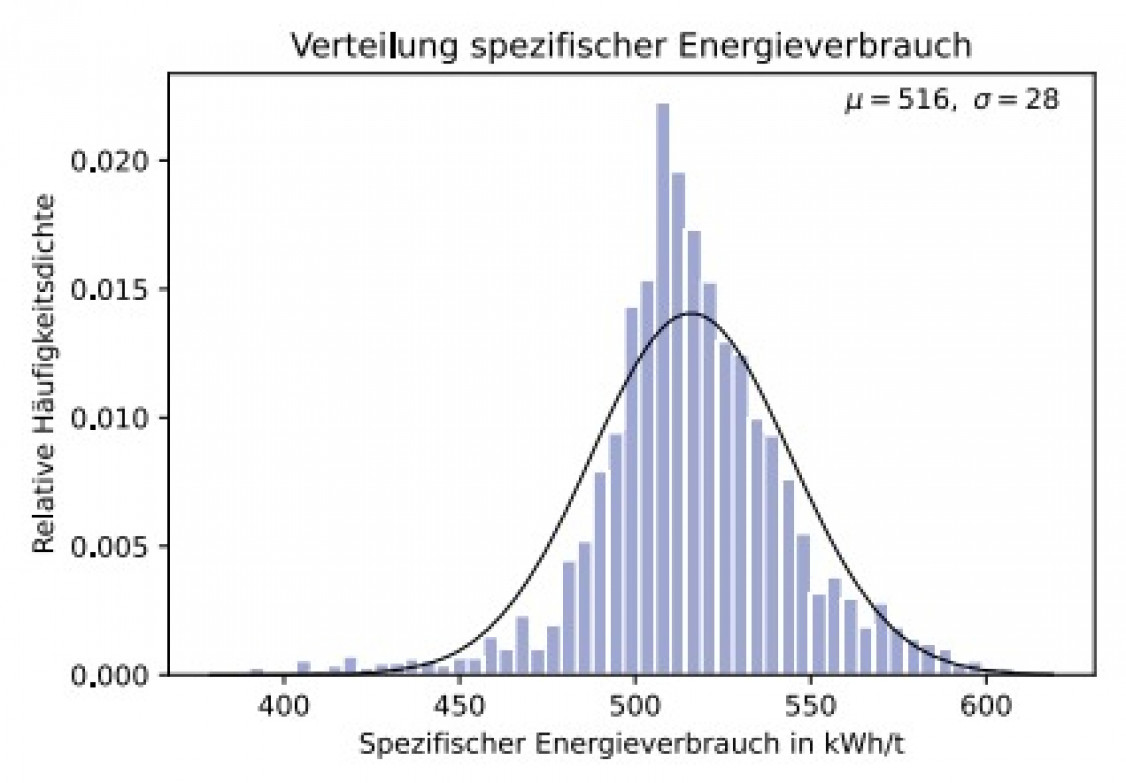
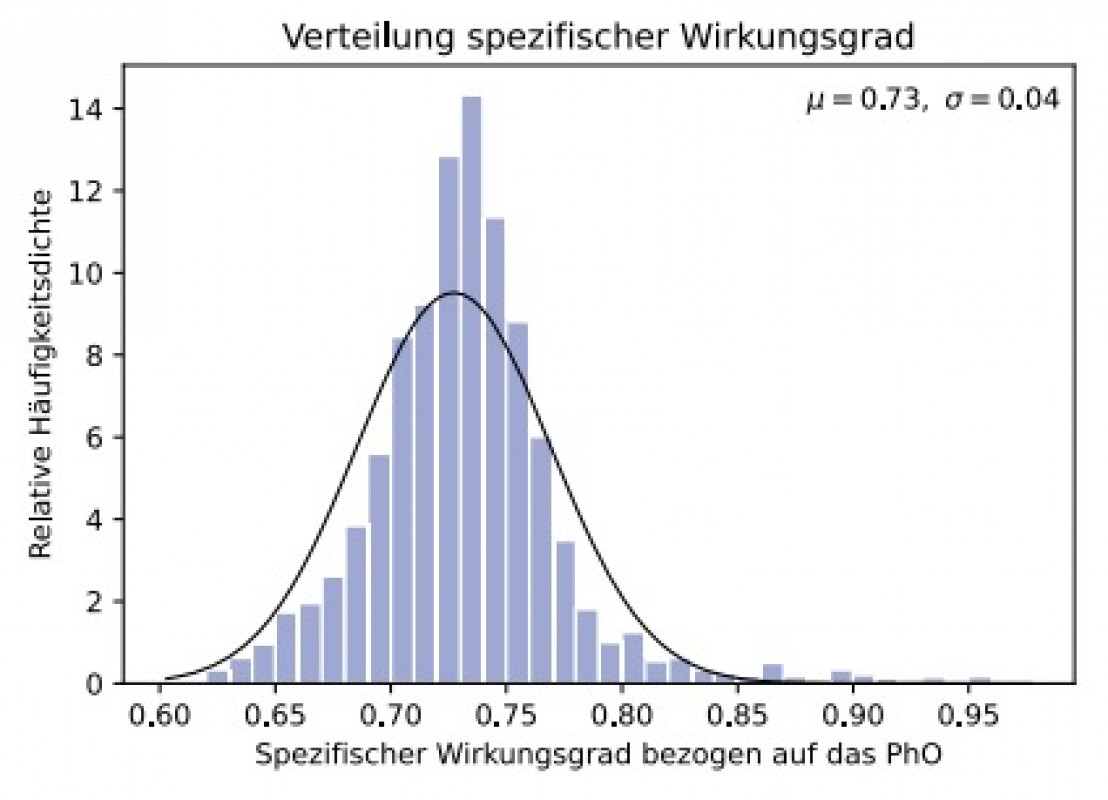
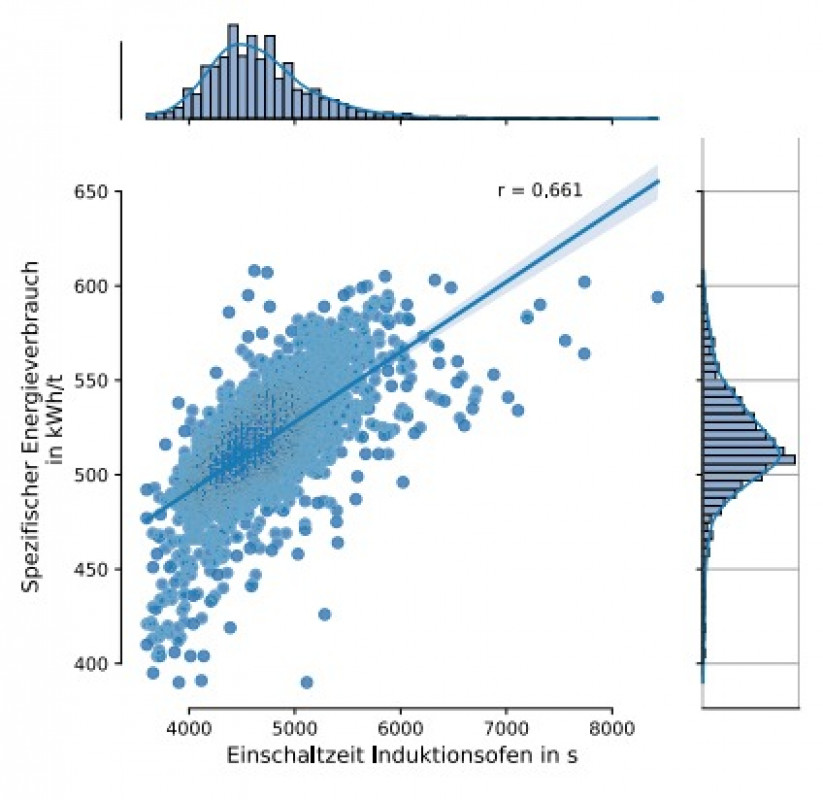
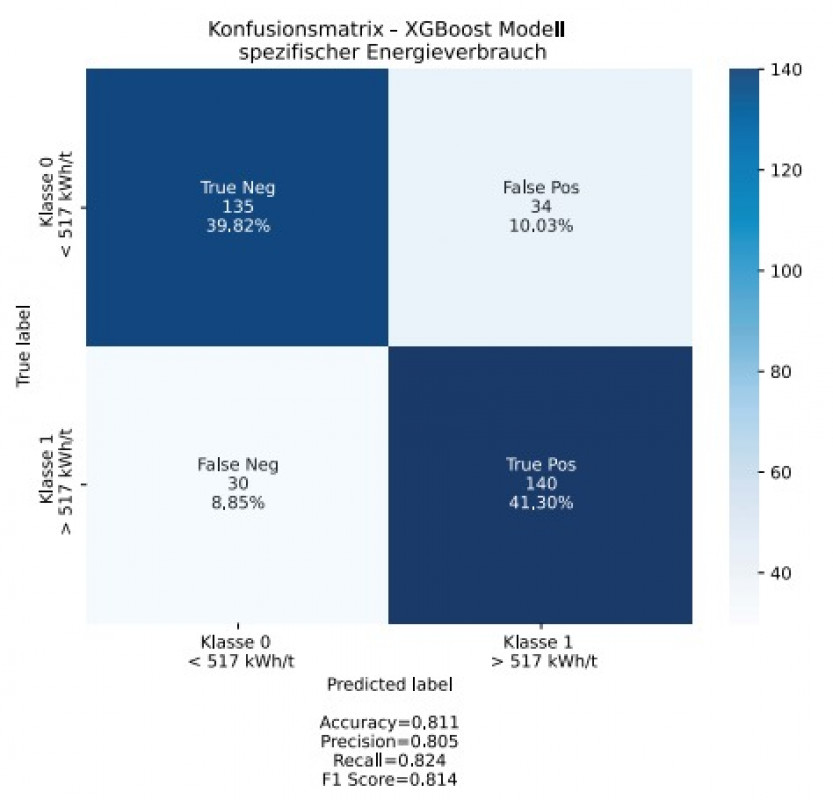
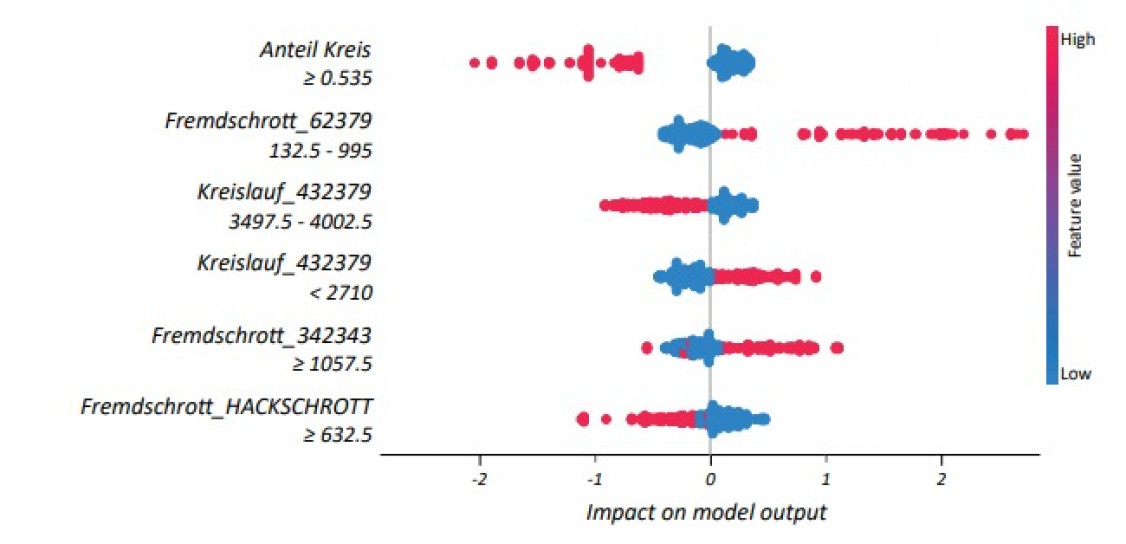
Zur Diskretisierung der Zielgröße (spezifischer Energieverbrauch) wurden die Daten in die zwei Gruppen Energieverbrauch kleiner (gelabelt als „0“) und größer (gelabelt als „1“) des Medians (517 kWh/t) aufgeteilt und anschließend mittels Maschinellem Lernen ein Modell zur Vorhersage der jeweiligen Klasse erstellt. Hierzu wurde das „XGBoost“-Framework [9] zur Modellerstellung (überwachtes Lernen) und das „SHAP-Framework“ [10] zur Modellinterpretation genutzt.
Maschinelles Lernen
Unter Maschinellem Lernen (ML) versteht man die Programmierung von Computern zur Optimierung eines Fähigkeitskriteriums anhand von Beispieldaten oder Erfahrungswerten. ML konzentriert sich auf die Entwicklung von Computerprogrammen, welche auf Daten zugreifen und diese nutzen, um automatisch für sich selbst Muster in den Daten zu lernen. Aufgrund der zunehmenden Menge und Vielfalt der verfügbaren Daten in der Prozessindustrie und der immer günstigeren und leistungsfähigeren Hardware können zunehmend komplexere, robustere und präzisere Systeme entwickelt werden. Diese sind in der Lage eine „intelligente“ Verarbeitung der Daten durchzuführen, weshalb das Maschinelle Lernen bzw. das Thema Künstliche Intelligenz in den letzten Jahren viel Aufmerksamkeit sowohl in der Öffentlichkeit als auch in der Forschung erhalten hat. In der Praxis lassen sich die Algorithmen des Maschinellen Lernens je nach ihrem Zweck in drei Hauptkategorien einteilen:
> Beim überwachten Lernen lernt ein ML-Modell aus Beispieldaten und zugehörigen Zielantworten, welche aus numerischen Werten oder String-Etiketten wie Klassen oder Tags bestehen können. Diese werden bei neuen Beispielen bzw. Input-Daten genutzt, um eine mögliche Antwort vorherzusagen. Überwachtes Lernen wird häufig in Anwendungen eingesetzt, bei denen historische Daten wahrscheinliche zukünftige Ereignisse vorhersagen. Im Allgemeinen werden Probleme des überwachten Lernens in Klassifizierung und Regression unterteilt. Bei Regressionsproblemen versucht das Modell, Ergebnisse innerhalb einer kontinuierlichen Ausgabe auf der Grundlage der kontinuierlichen Funktionen (Eingangsparameter, Merkmale oder auch Features genannt) vorherzusagen. Bei der Klassifizierung hingegen wird die Ausgabe lediglich als diskreter Wert vorhergesagt.
> Unüberwachtwes Lernen: Im Gegensatz zum überwachten Lernen, das anhand von markierten Beispielen trainiert wird, wird hier ein Lernmodell erstellt, indem Strukturen in den Eingabedaten ohne zugehörige Antwort abgeleitet werden, sodass der Algorithmus die Datenmuster selbständig bestimmen kann. Ein typisches Beispiel ist ein Empfehlungssystem, das Segmente von Kunden mit ähnlichen Merkmalen ermitteln kann. Solche Systeme finden beispielsweise zur Kategorisierung in Marketingkampagnen Anwendung. Populäre Techniken aus diesem Bereich sind z.B. das Clustering und die Dimensionsreduktion.
> Der Dritte Ansatz beschreibt das Verstärkungslernen. Hier geht es um die Frage, wie das Modell mit der Umwelt interagiert und in einer gegebenen Situation geeignete Handlungen auswählt, um die „Belohnung“ zu maximieren. Diese Art des Lernens wird häufig in der Robotik, bei digitalen Spielen und in der Navigation eingesetzt [11-13].
ML – Algorithmen
Zu jedem der oben genannten Bereiche gibt es eine Vielzahl an Methoden und Algorithmen, die alle einen anderen Ansatz des Lernens verfolgen. Ein künstliches neuronales Netz lernt gänzlich anders als ein auf Entscheidungsbäumen basierendes System, wie z.B. der Random Forest-Algorithmus. Die Auswahl des richtigen Algorithmus ist nicht einfach und hängt von den spezifischen Randbedingungen ab. Hierbei sind beispielsweise die Größe und Art der zu verwendenden Daten und die anvisierten Ergebnisse klassische Auswahlkriterien.
XGBoost.
Für die Modellerstellung in diesem Beitrag wurde der sogenannte XGBoost–Algorithmus genutzt. XGBoost (Extreme Gradient Boosting) ist eine skalierbare, verteilte GBDT-Bibliothek (Gradient-Boosted-Decision-Tree) für Maschinelles Lernen. Ein GBDT ist ein Ensemble-Lernalgorithmus für Entscheidungsbäume (ähnlich dem Random Forest) für Klassifizierung und Regression. Ensemble-Lernalgorithmen kombinieren mehrere maschinelle Lernalgorithmen, um ein besseres Modell im Vergleich zu ihren kompositionellen singulären Algorithmen zu erhalten. Entscheidungsbäume erstellen ein Modell, das eine Zielgröße vorhersagt, indem sie einen Baum von Wenn-dann-Falsch-Fragen mit wahr-/falsch-Merkmalen auswerten. Hieran wird die Mindestanzahl von Fragen geschätzt, die mit einer ausreichenden Wahrscheinlichkeit zu einer richtigen Prognose führen [14]. Entscheidungsbäume können zur Klassifizierung verwendet werden, um eine Kategorie vorherzusagen, oder zur Regression, um einen kontinuierlichen numerischen Wert vorherzusagen. Wenn es um kleine bis mittelgroße strukturierte/ tabellarische Daten geht, gelten Entscheidungsbaum-basierte Algorithmen wie der XGBoost derzeit als die Besten ihrer Klasse.
ML – Workflow
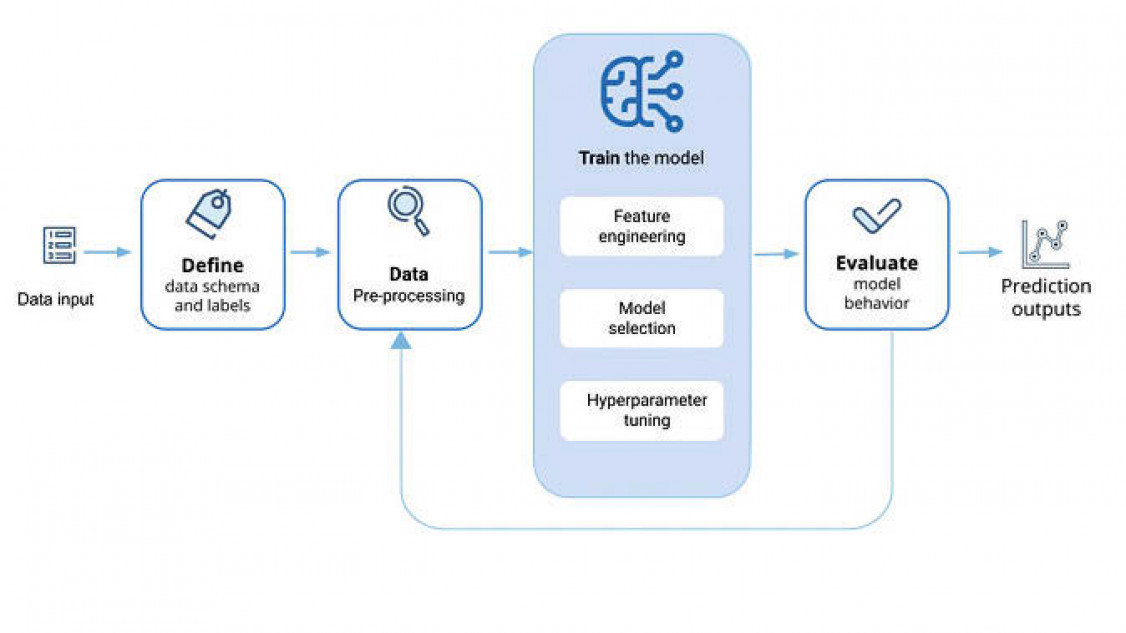
Der Workflow für Projekte, die mit Maschinellem Lernen gelöst werden sollen, stellt sich in der Regel immer gleich dar:
Datenerfassung.
Um ein Projekt zum Maschinellen Lernen zu beginnen, müssen zunächst Daten aus relevanten Quellen gesammelt werden. Dabei handelt es sich um das Abrufen relevanter Fertigungsinformationen, die Umwandlung der Daten in die erforderliche Form und das Laden in das vorgesehene Modell. Die in der Gießerei gesammelten Daten stammen aus verschiedenen Quellen, wie ERP-Datenbanken, IoT-Geräten, Ofensteuerungen usw.
Datenvorverarbeitung.
Sobald die Daten gesammelt sind, müssen sie vorverarbeitet werden. Dies umfasst das Bereinigen, Überprüfen und Formatieren der Daten zu einem geeigneten Datensatz und ist der wichtigste Schritt, der dazu beiträgt, Modelle für Maschinelles Lernen genauer in ihrer Prognose zu machen. Die allererste Maßnahme der Vorverarbeitung besteht darin, fehlende Daten zu identifizieren. Sie sind in den meisten realen Datensätzen üblich und solche Werte müssen zunächst bearbeitet werden, um die verfügbaren Daten optimal nutzen zu können. Eine grundlegende Strategie zur Nutzung unvollständiger Datensätze besteht darin, ganze Zeilen oder Spalten mit fehlenden Werten zu verwerfen. Dies hat jedoch den Nachteil, dass informative Daten verloren gehen, die für das Modelltraining wertvoll sein könnten. Eine Alternative dazu ist die Imputation. Diese strebt an, fehlende Werte aus dem bekannten Teil der Daten abzuleiten. Im Allgemeinen profitieren Lernalgorithmen von einer Standardisierung des Datensatzes, denn verschiedene Spalten innerhalb eines Datensatzes können in unterschiedlichen Wertebereichen vorhanden sein. So kann es beispielsweise eine Spalte mit der Einheit Prozent und eine andere mit der Einheit der Temperatur geben. Diese Spalten haben sehr unterschiedliche Wertebereiche, was es für viele Modelle des Maschinellen Lernens schwierig macht, einen optimalen Berechnungszustand zu erreichen. Es gibt einige Techniken, dieses Problem zu lösen: Standardisierung, Entfernung des Mittelwerts und Varianzskalierung (Skalierung von Merkmalen auf einen Bereich, oft zwischen Null und Eins, oder so, dass der maximale absolute Wert jedes Merkmals auf eine Einheitsgröße skaliert wird).
In vielen Fällen haben die Daten ein Format, welches von Algorithmen nicht verarbeitet werden kann. Eine Spalte mit String-Werten oder Text ist beispielsweise für ein Modell, das nur numerische Werte als Eingabe akzeptiert, bedeutungslos. Daher müssen kategorische Merkmale in ganzzahlige Codes umgewandelt werden, damit das Modell sie interpretieren kann. Diese Methode wird als kategoriale Kodierung bezeichnet. Zu den gängigen Ansätzen gehört die ordinale Kodierung, die Werte von 1 bis n ordinal einbettet, wobei n die Anzahl der Stichproben in der Spalte ist. Zusätzlich zu der Datenaufbereitung ist das sogenannte „feature engineering“ beim Erstellen von ML-Modellen wichtig für die Modellperformance. Hierunter versteht man das Erstellen von neuen Merkmalen („Features“) aus den Rohmerkmalen. So können zum Beispiel Tag, Monat und Jahr aus einer Datum-Zeit-Spalte extrahiert werden. Dadurch erhält das Modell eine neue Perspektive und kann nun eine ganz neue Beziehung zwischen der Zeit und der Zielvariablen erkennen.
In ähnlicher Weise ist die Diskretisierung ein Prozess, bei dem kontinuierliche Merkmale in diskrete Werte aufgeteilt werden. Bestimmte Datensätze mit kontinuierlichen Merkmalen können von der Diskretisierung profitieren, da sie den Datensatz mit kontinuierlichen Attributen in einen solchen mit nur nominalen Attributen umwandeln kann. Es kann zudem sinnvoll sein, die Komplexität des Modells durch Berücksichtigung nichtlinearer Merkmale der Eingabedaten zu erhöhen. Eine gängige Methode ist die Verwendung polynomialer Merkmale, z. B. können die Merkmale von X von (X1, X2) in (1, X1, X2, X1*X2, X1 2, X2 2) transformiert werden. Ein Anwendungsbeispiel im genutzten Datensatz ist das Summieren von bestimmten Schrottkategorien des Originaldatensatzes zu einer Überkategorie, z.B. die Summe aller „Fremdschrotte_Hackschrotte“ einer Gattierung zu einer neuen Spalte im Datensatz zu ergänzen.
Training des Modells.
Bevor das Modell trainiert wird, müssen die Daten in Trainings- und Testdaten aufgeteilt werden. Das Trainingsset wird verwendet, um den Algorithmus zunächst zu trainieren und ihm „beizubringen“, wie er Informationen verarbeiten soll. Der Testdatensatz wird verwendet, um die Genauigkeit und Leistung des Modells im Anschluss an das Training zu überprüfen. Sobald der Datensatz für das Training bereit ist, besteht der nächste Schritt darin, den Algorithmus mit dem Trainingssatz anzulernen, damit er geeignete Parameter und Merkmale für den Lernprozess erlernen kann. Um die Leistung des Modells für das Klassifikationsproblem zu beurteilen, werden die folgenden Bewertungsmetriken [9] genutzt, wobei im Kontext dieses Artikels gilt:
> True positive (TP): Der spezifische Energieverbrauch liegt in Klasse 0 (< 517 kWh/t) und das Modell hat dies richtig prognostiziert.
> True negative (TN): Der spezifische Energieverbrauch liegt in Klasse 1 (> 517 kWh/t) und das Modell hat dies richtig prognostiziert.
> False negative (FN): Der spezifische Energieverbrauch liegt in Klasse 1, aber das Modell hat ihn fälschlicherweise als Klasse 0 prognostiziert.
> False positive (FP): Der spezifische Energieverbrauch liegt in Klasse 0, aber das Modell hat ihn fälschlicherweise als Klasse 1 prognostiziert.
Accuracy.
Die Genauigkeit wird als statistisches Maß dafür verwendet, wie korrekt ein binäres Klassifikationsmodell einen Zustand identifiziert oder ausschließt. Das heißt, die Genauigkeit ist der Anteil der korrekten Vorhersagen (sowohl wahrpositive als auch wahr-negative) an der Gesamtzahl der untersuchten Fälle. Es ist das Verhältnis zwischen der Anzahl der richtigen Vorhersagen und der Gesamtzahl der Stichproben:
Accuracy = (TP+TN)/(TP+TN+FP+FN)
Precision.
Die Präzision ist der Prozentsatz der Vorhersagen, die richtig (positiv) waren. Je höher sie ist, desto weniger falsch-positive Vorhersagen werden getroffen. Wenn das Modell beispielsweise prognostizieren soll, ob eine Gattierung einen geringen (Klasse 0) oder hohen (Klasse 1) Energieverbrauch beim Schmelzen induzieren wird, bedeutet ein Präzisionswert von 0,2, dass das Modell 20 % aller Klassenzuordnungen in den Testdaten korrekt identifiziert.#
Precision = TP/(TP+FP)
Recall.
Der Prozentsatz aller Elemente der Grundwahrheit, die vom Modell erfolgreich vorhergesagt wurden. Je höher der Recall-Wert ist, desto weniger falsch-negative Vorhersagen wurden getroffen.
Recall = TP/(TP+FN)
F1-Score.
Der F1-Score ist das harmonische Mittel aus Precision und Recall oder eine Art gewichteter Durchschnitt der beiden Metriken.
F1-Score = 2*(Precision*Recall)/(Precision+Recall)
Grundsätzlich „bestraft“ der F1-Score Modelle, die zu stark auf Präzision oder Recall ausgerichtet sind, und ist somit eine gute Metrik zur Messung der Gesamtleistung eines Modells.
Konfusionsmatrix.
Eine Konfusionsmatrix fasst die Klassifizierungsleistung eines Klassifikationsmodells in Bezug auf die Testdaten zusammen. Es handelt sich um eine zweidimensionale Matrix, die in einer Dimension durch die wahre Klasse eines Objekts und in der anderen durch die Klasse, die das Modell zuordnet, indiziert ist. Die Matrix ist eine Zusammenfassung der Vorhersageergebnisse für ein Klassifizierungsproblem. Die Anzahl der richtigen und falschen Vorhersagen wird mit Zählwerten zusammengefasst und nach den einzelnen Klassen aufgeschlüsselt.
Modellbewertung.
Nachdem ein akzeptabler Satz von Hyperparametern (Parameter, die zur Steuerung des Trainingsalgorithmus verwendet werden und dessen Werte im Gegensatz zu anderen Parametern vor dem eigentlichen Training des Modells festgelegt werden müssen, wie z.B. maximale Tiefe eines Baumes im ganzen Entscheidungsbaum) gefunden und die Modellleistung optimiert wurde, kann das Modell schließlich getestet werden. Dabei wird der Testdatensatz verwendet, um zu überprüfen, wie genau die Modelle das gewünschte Ergebnis prognostizieren können. Auf der Grundlage des erhaltenen Feedbacks kann man zum Training des Modells zurückkehren, um die Leistung zu verbessern, die Ausgabeeinstellungen anzupassen oder das Modell nach Bedarf einzusetzen. Bild 2 zeigt den typischen Workflow eines ML-Projektes auf.