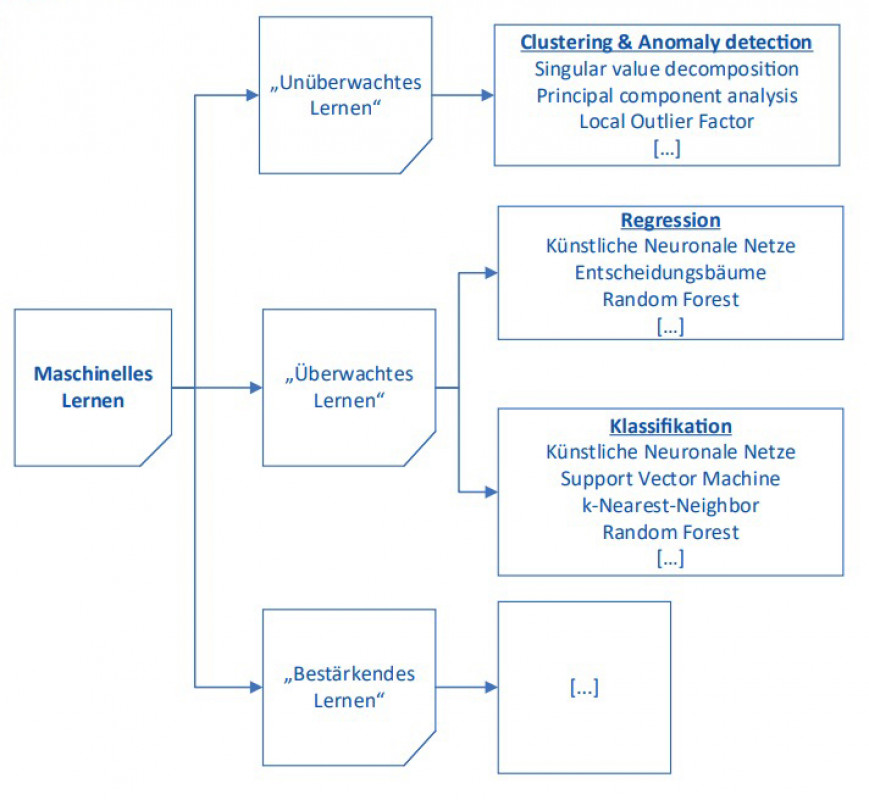
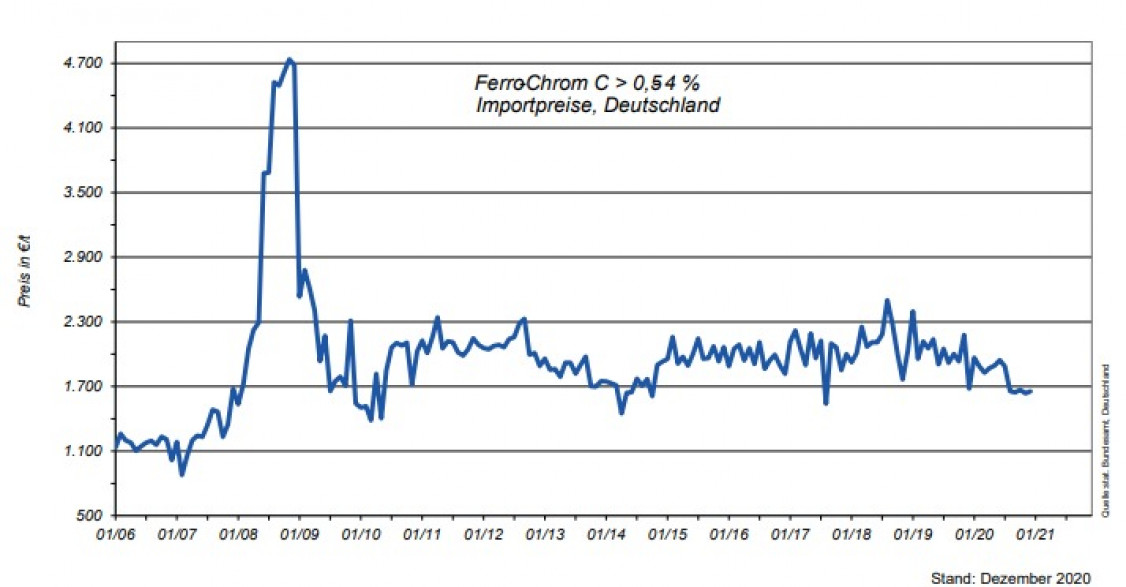
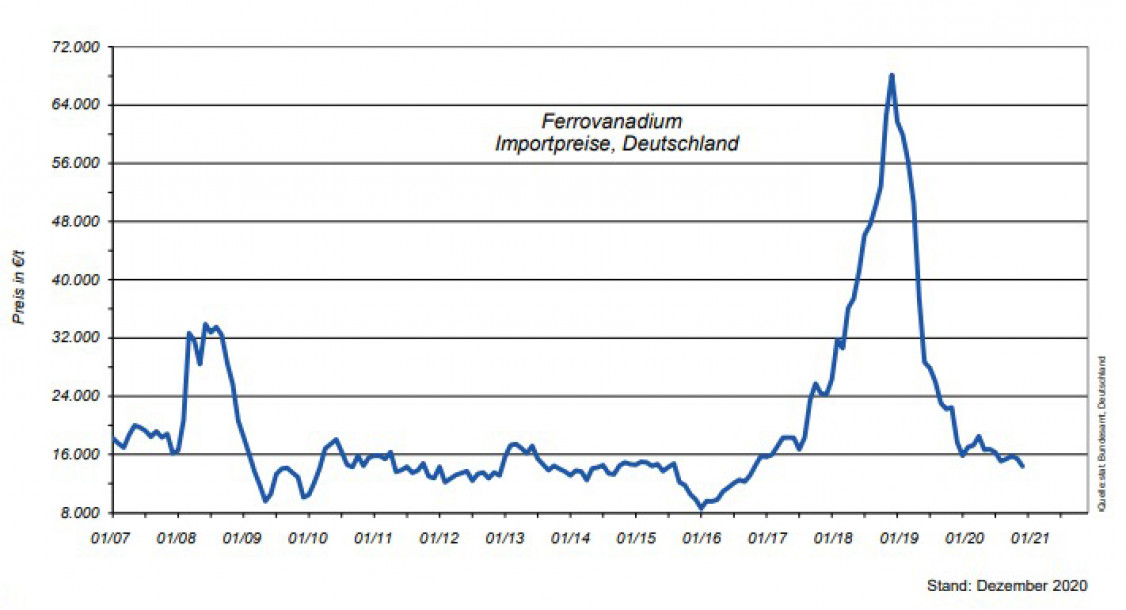
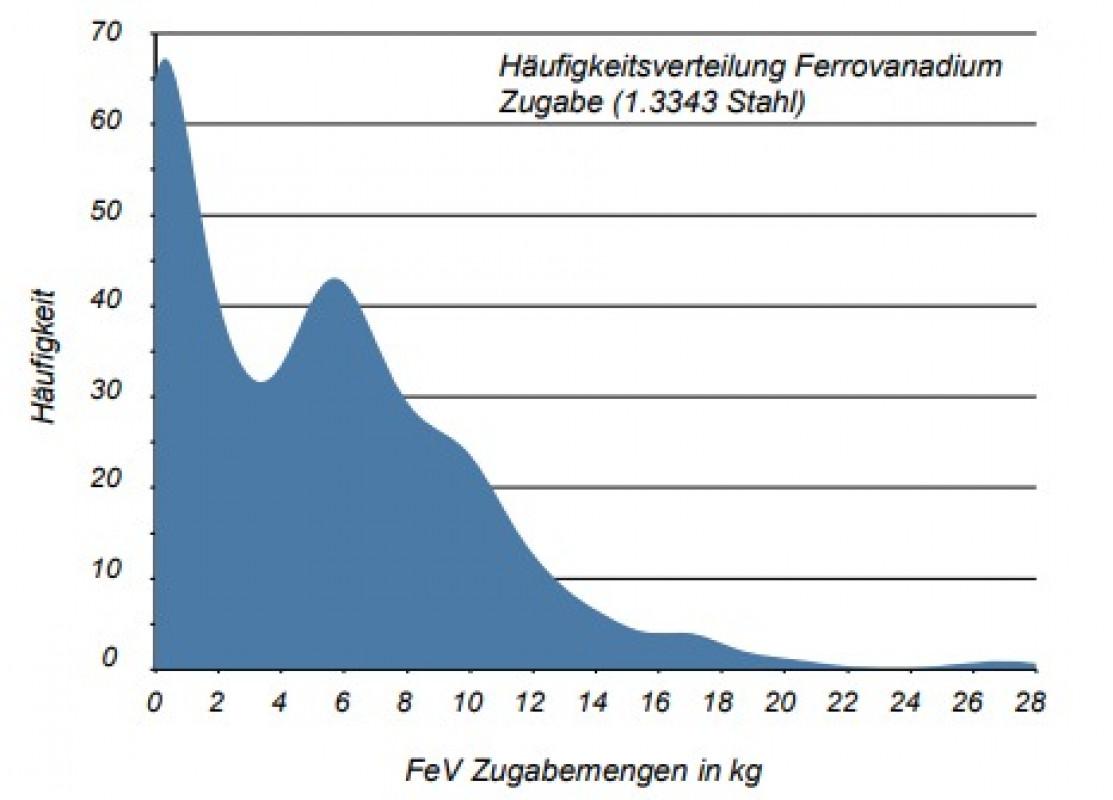
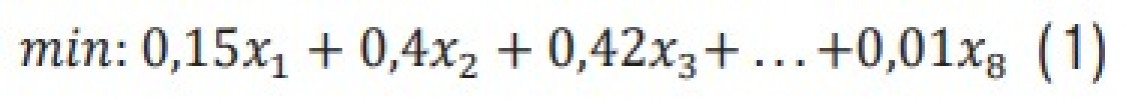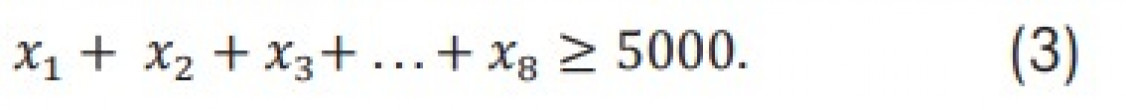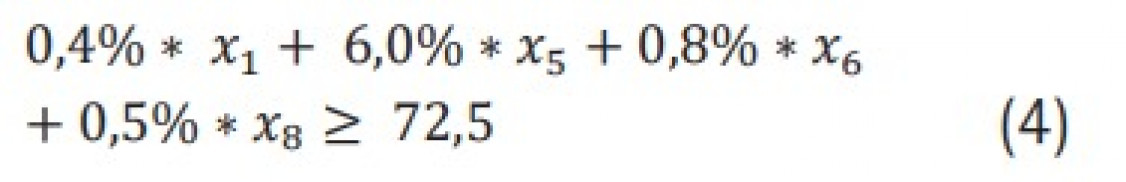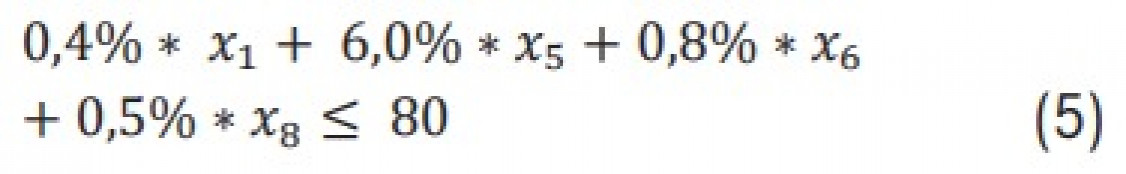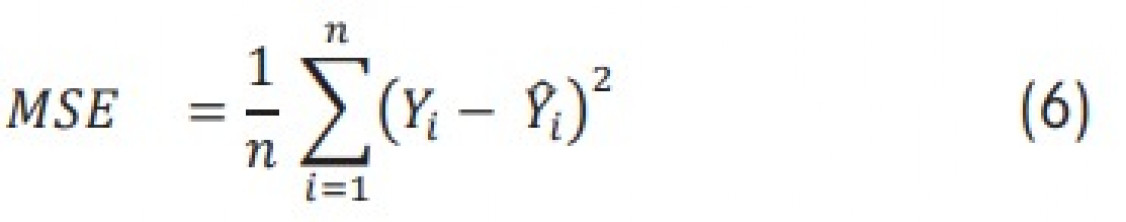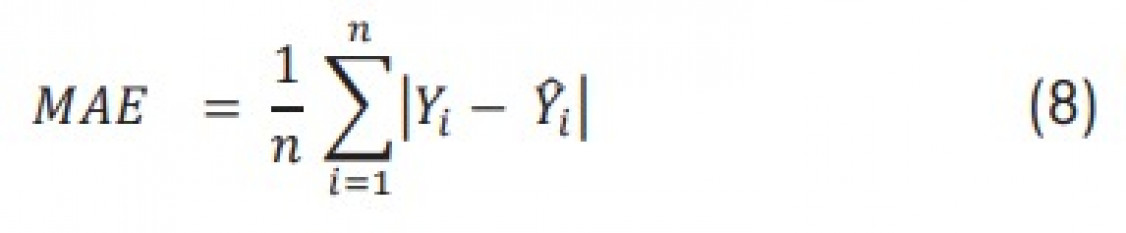Während bei der Regression die neuronalen Netze bezüglich der Prognosegüte hinter Algorithmen wie z.B. Random Forest liegen, zeigen sie bei der Klassifikation die besten Gesamtergebnisse (79 % Classification Accuracy). Die Klassen 1 (FeV-Zugabe 0 - 5 kg) und 3 (FeVZugabe 10 - 15 kg) können durch neuronale Netze mit ca. 85 % bzw. 87 % Genauigkeit prognostiziert werden, Klasse 2 (FeV-Zugabe 5 - 10 kg) hingegen nur mit knapp 68 %.
Fazit
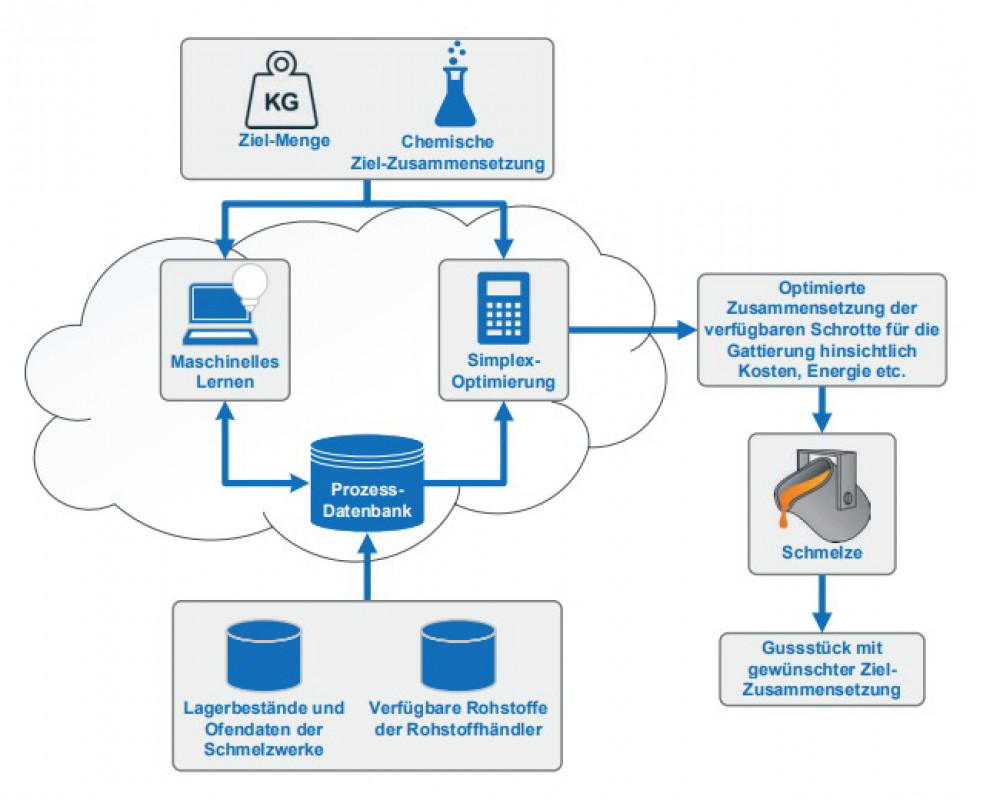
Es wurde eine innovative Methode vorgestellt, die mithilfe von datenbasierten Prognosemodellen sowie linearer Optimierung die Auswahl der Gattierung und das Schmelzen von Metallen im Induktionsofen hinsichtlich Ressourcen- und Energieeffizienz optimiert. Dabei ergänzt das Maschinelle Lernen die rein monetäre Sicht der linearen Optimierung um metallurgisches Wissen.
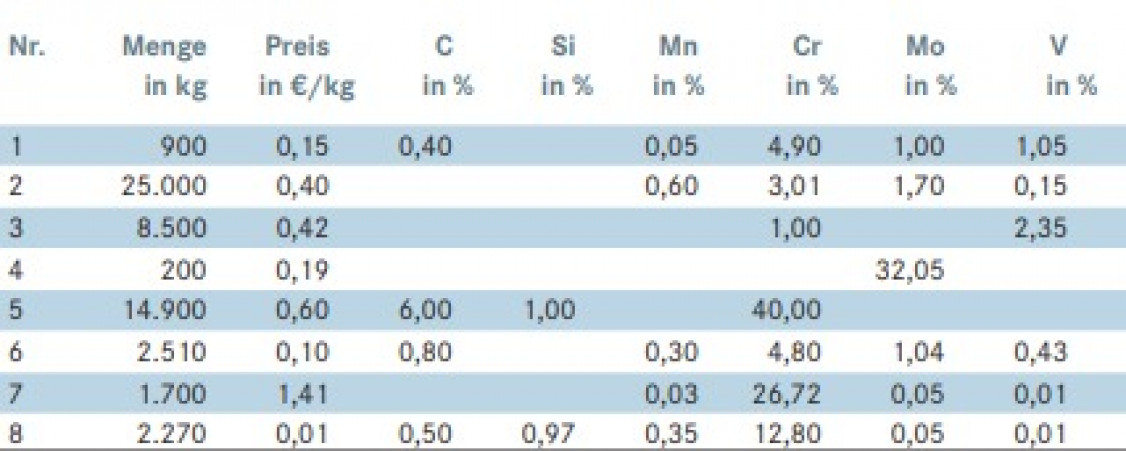
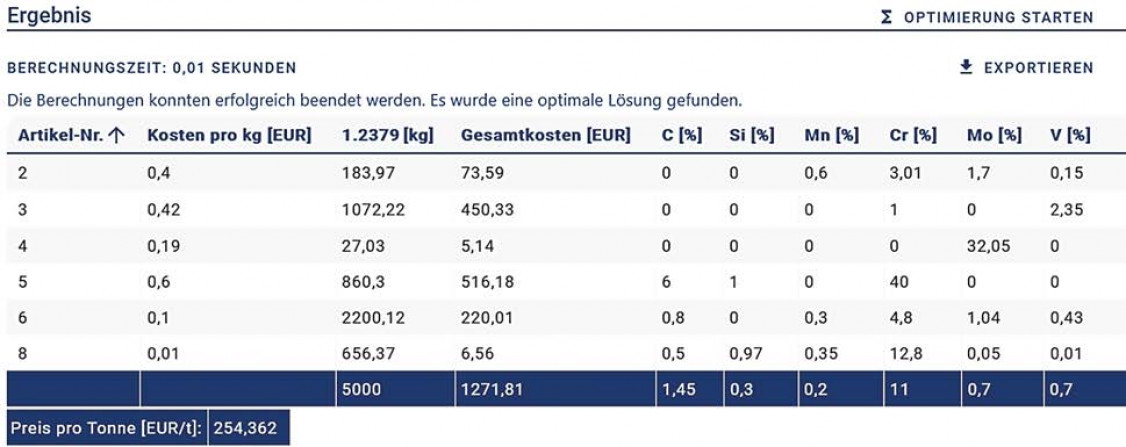
Die Simplex-Methode als Algorithmus der linearen Optimierung liefert bei entsprechender Datengrundlage in nahezu Echtzeit ein optimiertes Ergebnis hinsichtlich der Kosten. Über die Oberfläche einer Web-Anwendung können Nutzer eine Vielzahl von Nebenbedingungen hinzufügen, ohne die Performance der Berechnungen zu beeinträchtigen. Die Schnelligkeit lässt sich auf die Neu-Implementierung des Algorithmus in der Programmiersprache C# zurückführen. Die Brauchbarkeit der Ergebnisse hängt jedoch stark von den übergebenen Daten ab. Repräsentieren diese das metallurgische Problem nicht ausreichend, ist das zurückgegebene Ergebnis nach dem Schmelzen nicht zwangsläufig die günstigste Option, sodass ein Nachjustieren mit in der Regel teuren Primärrohstoffen erforderlich wird. Daher ist das Zuführen metallurgischer Einflussparameter über ML-Modelle notwendig.
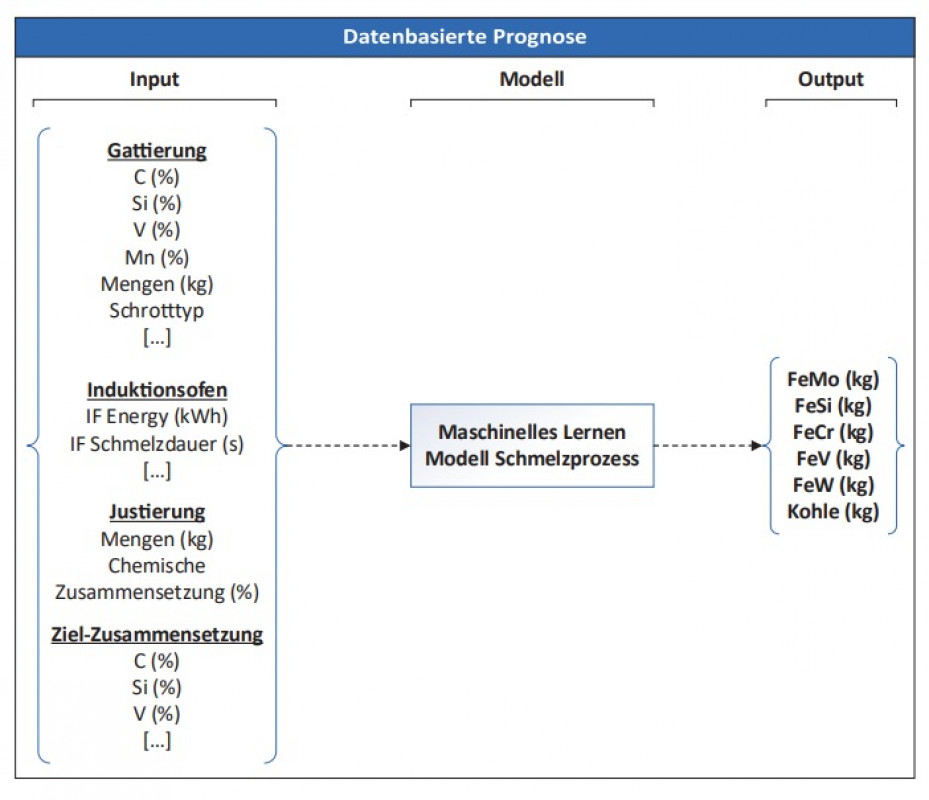
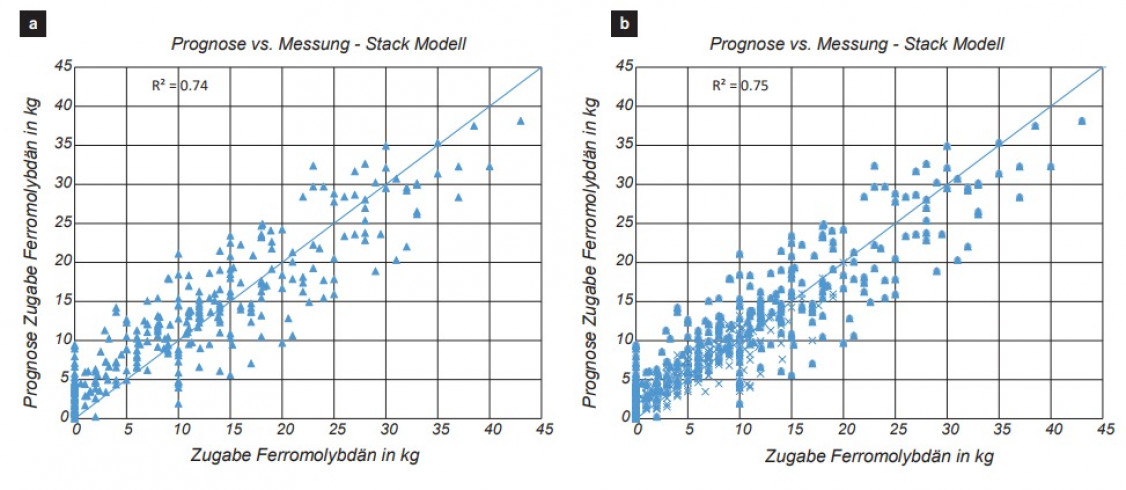
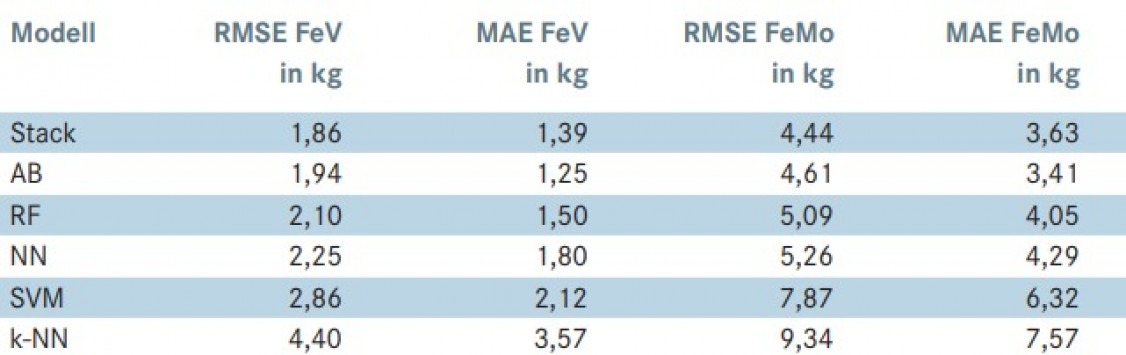
Die datengetriebenen Prozessmodelle zeigen erste vielversprechende Ergebnisse bzgl. der Prognosegüte bei der Modellierung des Schmelzprozesses im Induktionsofen; eine verbesserte Datenbasis kann hier in Zukunft helfen, noch genauere Prognosemodelle zu erstellen. Als Beispiel wurde gezeigt, wie anhand der verfügbaren Daten der Rohstoffe und den Prozessparametern des Induktionsofens sowie der gewünschten Ziel-Zusammensetzung die zu erwartende Menge an benötigten Ferrolegierungen vorausgesagt werden kann. Besonders die Methodik des „Stacking“ von unterschiedlichen ML-Algorithmen zeigte bei der Regression die besten Prognoseergebnisse. Betrachtet man die unterschiedlichen Algorithmen im Einzelnen, so weisen die Random-Forest-Entscheidungsbäume die besten Ergebnisse auf. Bei der Umwandlung des Modells in ein Klassifikationsmodell zeigen hingegen die neuronalen Netze die besten Ergebnisse. Je nach Art der zu untersuchenden Daten und der aus prozesstechnischer Sicht relevanten Größen sollte entweder ein Regressions- oder Klassifikationsmodell erstellt werden. Prinzipiell lässt sich die hier vorgestellte Methode auf jede Art von Gießprozess (Eisenguss, Aluminiumguss etc.) sowie gewünschte Zielgröße (z.B. Ausschussreduzierung, Energieoptimierung etc.) anwenden.
Grundlage ist eine fundierte Digitalisierung des Fertigungsprozesses, was in der aktuellen Gießereilandschaft wahrscheinlich die in Zukunft größte zu überwindende Hürde sein wird. Die Implementierung dieser modernen digitalen Technologien in den Fertigungsprozess ist daher kein einfaches Unterfangen. Oftmals werden zusätzliche Sensorik, IT-Systeme und zusätzliches Personal benötigt; einen „schnellen“ und sofort sichtbaren Effekt können solche Systeme nicht immer erzielen. Eine sinnvolle Implementierung und Abstimmung der einzelnen Systeme wird benötigt, was nur durch eine Verfügbarkeit von Prozessdaten und deren sorgfältiger Auswahl erreichbar ist. Ist dies aber einmal geschafft, werden diese Methoden dabei helfen, die Wettbewerbsfähigkeit der deutschen Gießerei-Industrie auch in Zukunft zu erhalten und in einiger Zeit einen wichtigen Beitrag zur ressourcen- und energieeffizienten Fertigung leisten.
Die vorgestellten Arbeiten stammen aus dem Projekt „Optimierung der Rohstoffproduktivität in der Gießerei- und Stahlindustrie aus Produkten der Recyclingwirtschaft durch Nutzung moderner mathematischer Verfahren, Vernetzung und Digitalisierung“ (OptiRoDig). Das vom Bundesministerium für Bildung und Forschung (BMBF) geförderte Vorhaben wurde im Rahmen des Förderaufrufs „Ressourceneffiziente Kreislaufwirtschaft – Innovative Produktkreisläufe (ReziProk)“ ins Leben gerufen.
In diesem Projekt sind die beiden Firmen Friedr. Lohmann GmbH und RHM Rohstoff-Handelsgesellschaft mbH involviert. An dieser Stelle möchten wir uns bei den Projektverantwortlichen beider Firmen bedanken; insbesondere bei Herrn Dipl.-Ing. Friedrich Lohmann-Voß und Christoph Jonas, M.Sc.
Weitere Informationen
Universität Duisburg-Essen
Mathematik für Ingenieure
Prof. Dr. rer. nat. Johannes Gottschling,
Annika Tonnius, M.Sc.
Forsthausweg 2
47057 Duisburg
E-Mail: johannes.gottschling@uni-due.de, annika.tonnius@uni-due.de
www.uni-due.de/mfi/
Hochschule für angewandte
Wissenschaften Kempten
Labor für Werkstofftechnik und
Betriebsfestigkeit
Prof. Dr.-Ing. Dierk Hartmann,
Tim Kaufmann, M.Sc.
Bahnhofstrasse 61
87435 Kempten
E-Mail: dierk.hartmann@hs-kempten.de, tim.kaufmann@hs-kempten.de
www.hs-kempten.de
Literatur
[1] The Arabian Journal for Science and Engineering 29 (2004), [Nr. 1B], pp. 65–81.
[2] Engineering Applications of Artificial Intelligence 21 (2008), [Nr. 7], pp. 1001–1012.
[3] International Journal of Advanced Manufacturing Technologies (2008), [Nr. 39], pp. 1111–1124.
[4] International Journal of Metallurgy 11 (2017), pp. 255–265.
[5] Tsoukalas, V. An adaptive neuro-fuzzy inference system (ANFIS) model for high pressure die casting. Proc. Inst. Mech. Eng. Part. B J. Eng. Manuf. 2011, 225, 2276–2286.
[6] Götz, Fuchslocher: „BMW setzt auf Data Analytics in der Leichtmetallgießerei“, unter: https://www.automotiveit.eu/ technology/bmw-setzt-auf-data-analyticsin-der-leichtmetallgiesserei-215.html (abgerufen am 20.02.2021).
[7] GIESSEREI PRAXIS (2018), [Nr. 12], pp. 9–15.
[8] Management Science 35 (1989), [Nr.3], pp. 367-371.
[9] Environmental Science & Technology 51 (2017), [Nr. 22], pp. 13086-13094.
[10] GIESSEREI PRAXIS (2018), [Nr. 10], pp. 11–17, 2018.
[11] Hochstättler, W.: Lineare Optimierung, Berlin: Springer Spektrum, 2017.
[12] Raschka, S., Mirjalili, V.: Machine Learning mit Python und Scikit-Learn und TensorFlow: Das umfassende Praxis-Handbuch für Data Science, Predictive Analytics und Deep Learning. MITP-Verlags GmbH & Co. KG, 13. Dezember 2017, ISBN 978-3-95845-735-5.
[13] Usama M. Fayyad, Keki B. Irani: Multi-interval discretization of continuousvalued attributes for classification learning. In: Thirteenth International Joint Conference on Artificial Intelligence, 1022-1027, 1993.